Sakana Fugu: One Model API to Orchestrate All the Others
Sakana Fugu Ultra orchestrates multiple LLMs via one API and claims Fable 5-level benchmarks — but Ethan Mollick's shader tests show 30-minute runs and results that fall short of Fable in practice. Full breakdown of claims vs early testing.
AI AgentsMulti-Agent SystemsFoundation ModelsAI Sovereignty
LLMs
Orchestration
There's a new way to think about frontier AI performance: don't build a bigger model, build a smarter coordinator.
Sakana Fugu, released today by Sakana AI, is the first production model built on this premise. It's a multi-agent orchestration system that presents itself as a single foundation model — you call one API endpoint, and internally Fugu decides whether to answer directly or assemble a team of specialized models to handle it. The complexity never reaches your code.
And the benchmarks are hard to dismiss — on paper. Fugu Ultra matches Anthropic's Fable 5 and Mythos Preview across Sakana's published engineering, scientific, and reasoning tables — while neither of those models is even in its agent pool. They can't be. They're subject to export controls.
Update (June 23, 2026): Within 24 hours of launch, independent testers — led by Ethan Mollick, who runs some of the community's most-watched creative-coding experiments — reported a sharp gap between benchmark claims and real use. Shader and interactive-scene tests took 30 minutes on Fugu Ultra-high. Output was "fine" but did not match Fable in practice. See Real-world testing below.
That last part is still the point for sovereignty — but the performance story is now more complicated than launch-day headlines suggested.
Sakana AI introduces Fugu: one API that coordinates multiple frontier models under the hood.
One thing to get clear before going further: Fugu is not a frontier model. It's a model orchestrator. It doesn't replace Opus, GPT-5.5, or Gemini — it coordinates them. Fugu is the conductor; the frontier models in its pool are the orchestra. Without those underlying models, there's nothing to orchestrate. What Fugu brings is the intelligence layer that decides which model handles which part of a task, routes dynamically, and synthesizes the outputs into one coherent answer. If you're already paying for API access to multiple providers, Fugu is the glue that makes the collective smarter than any individual piece.
For the past few years, progress in AI meant one thing: bigger models, more compute, more data. It worked. But it also created a concentration problem that is no longer theoretical.
Anthropic's Fable 5 and Mythos models — today's most capable frontier models — recently had export controls imposed on them. Organizations that built critical infrastructure on those APIs found their access could shift or disappear overnight due to regulatory boundaries and foreign policy decisions.
Sakana's answer isn't a new mega-model. It's a system designed so that no single provider is a point of failure.
"Collective intelligence serves as the practical hedge against this concentration of power."
— Sakana AI
Fugu's agent pool is explicitly swappable. If a provider restricts access, Fugu routes around the disruption. As new models arrive — including Sakana's own — they fold into the pool and pass the gains to users automatically.
What Fugu Actually Is
Fugu is itself a language model. Not a wrapper or a router built with if/else logic — a trained orchestrator that has learned:
When to delegate vs. solve directly
How to break complex tasks into agent subtasks
How agents should communicate with each other
How to combine their outputs into a single, reliable answer
This is built on two ICLR 2026 papers from Sakana AI: TRINITY (an evolved LLM coordinator) and Conductor (learning to orchestrate agents in natural language). The academic grounding matters — this isn't prompt engineering dressed up as a product.
From the outside, you call one model. On the inside, a coordinated system of experts does the work.
Fugu vs. Fugu Ultra
Both models share the same OpenAI-compatible API.
Fugu
Fugu Ultra
Optimized for
Low latency, everyday tasks
Maximum quality, complex tasks
Best use cases
Code review, chatbots, Codex-style tools
Research, security assessment, patent analysis
Compliance controls
Opt specific agents out of pool
Same
Latency
Lower
Higher (deeper coordination)
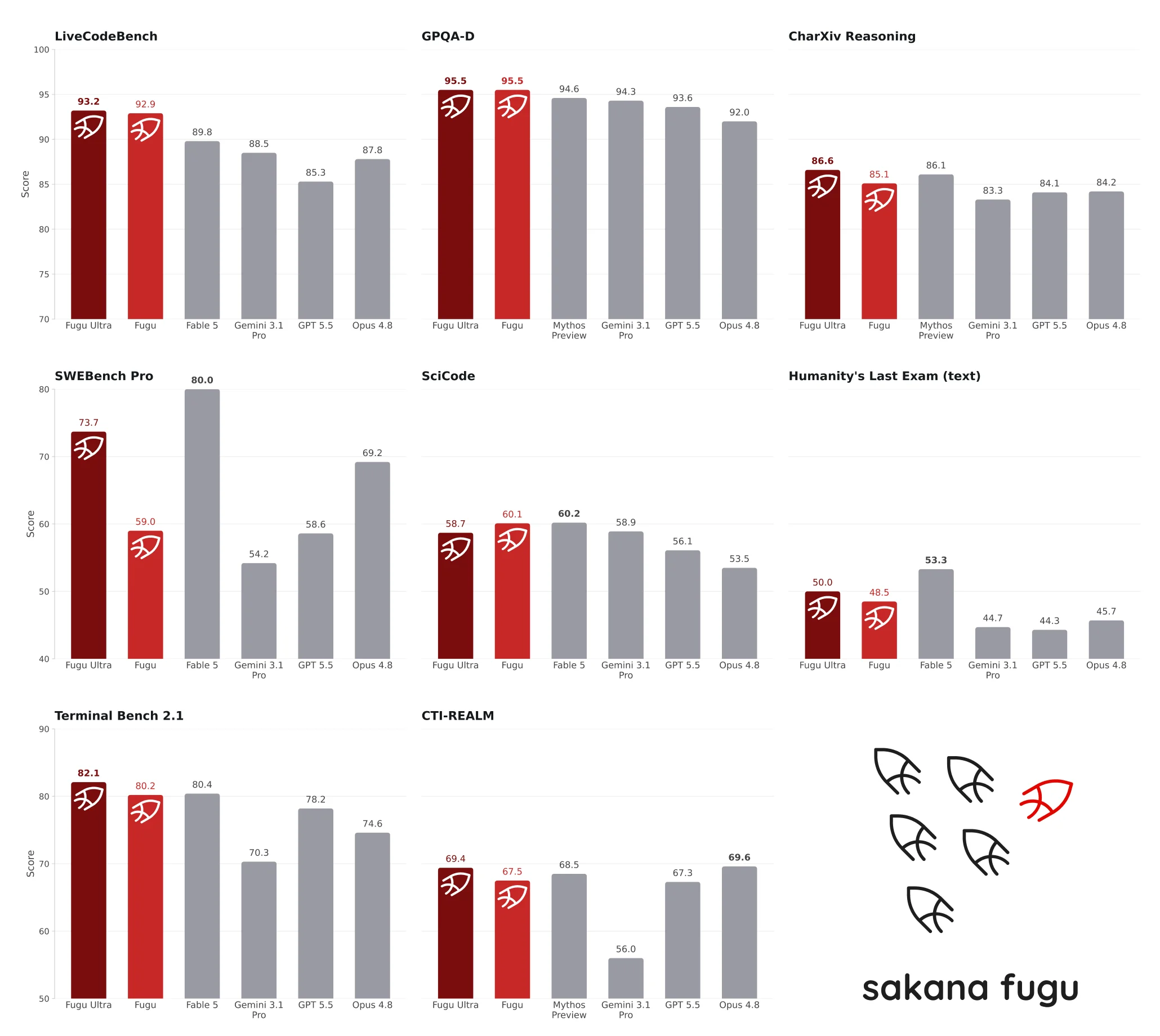
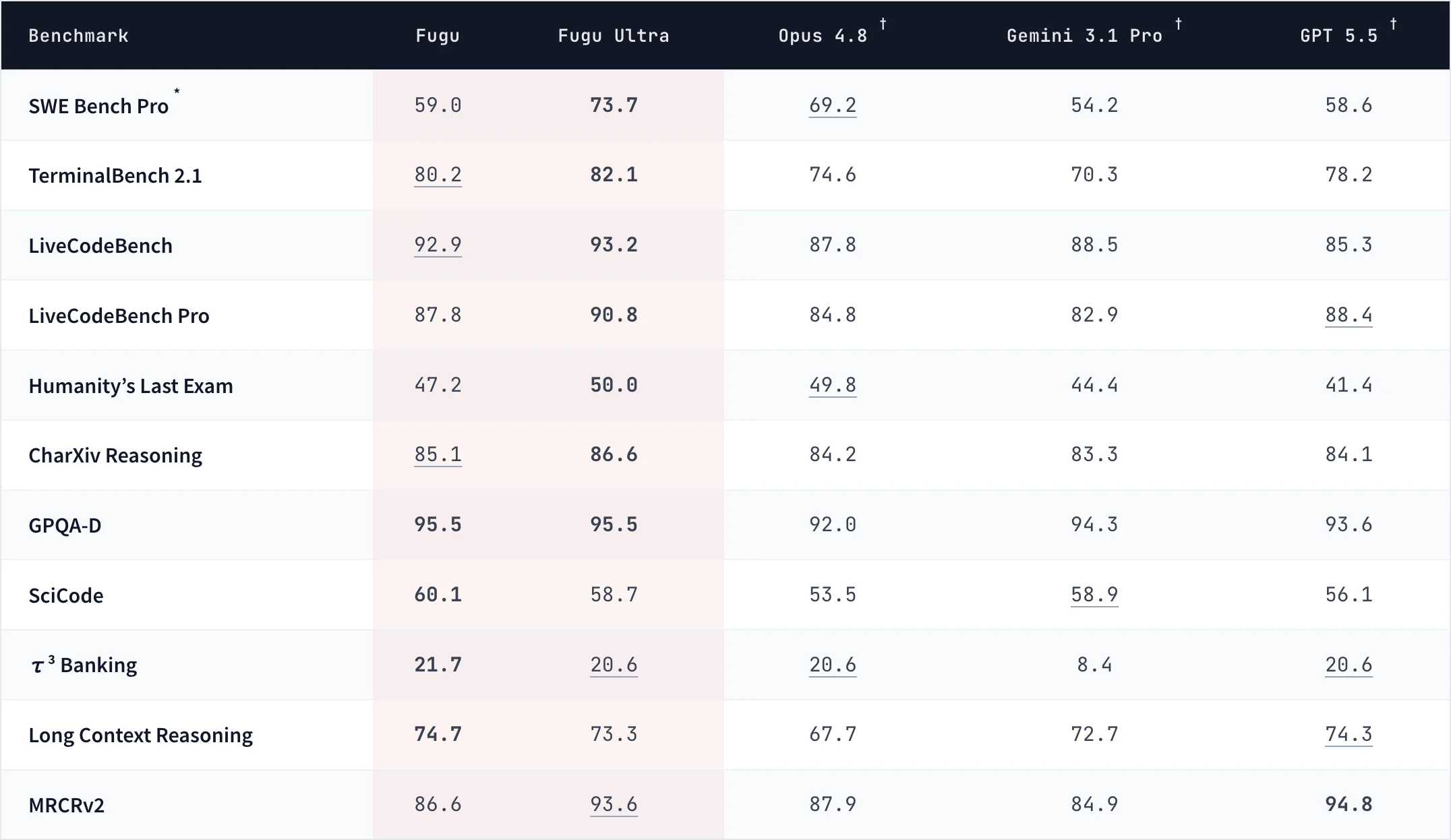
The Benchmark Numbers
Fugu Ultra goes head-to-head with today's frontier models across coding, reasoning, scientific, and agentic benchmarks. The comparison is against Opus 4.8 (Anthropic's best publicly accessible model), Gemini 3.1 Pro, and GPT-5.5 — not Fable 5 or Mythos, which are under export controls and not in Fugu's pool.
Key results at a glance:
Benchmark
Fugu
Fugu Ultra
Opus 4.8
Gemini 3.1 Pro
GPT-5.5
SWE Bench Pro
59.0
73.7
69.2
54.2
58.6
TerminalBench 2.1
80.2
82.1
74.6
70.3
78.2
LiveCodeBench
92.9
93.2
87.8
88.5
85.3
LiveCodeBench Pro
87.8
90.8
84.8
82.9
88.4
Humanity's Last Exam
47.2
50.0
49.8
44.4
41.4
CharXiv Reasoning
85.1
86.6
84.2
83.3
84.1
GPQA-D
95.5
95.5
92.0
94.3
93.6
SciCode
60.1
58.7
53.5
58.9
56.1
Long Context Reasoning
74.7
73.3
67.7
72.7
74.3
MRCRv2
86.6
93.6
87.9
84.9
94.8
Fugu Ultra leads or ties on 8 of 10 benchmarks. The standard Fugu model leads on SciCode and Long Context Reasoning — suggesting the lighter model is better calibrated for document-heavy tasks where over-coordination adds noise.
Fugu Ultra vs Fable 5: Benchmarks vs Real Use
This is the headline Sakana is leading with — and it needs careful unpacking.
Sakana explicitly claims Fugu Ultra "stands shoulder-to-shoulder" with Fable 5 and Mythos Preview on published benchmark tables. Importantly, neither model is in Fugu's agent pool — they're under export controls and not publicly accessible. Fugu achieves its scores by orchestrating models that are accessible, then synthesizing their outputs.
On paper, the implication is clear: you don't need access to Fable 5 to get Fable 5-level results.
Ethan Mollick (@emollick) — the Wharton professor whose Fable 5 shader experiments became an informal community benchmark — spent launch weekend on Sakana Fugu Ultra-high. His verdict, posted June 22–23:
"I have been trying Sakana Fugu Ultra-high and, first, it is incredibly slow: my typical coding tests (shaders, interactive scenes) take 30 minutes to run. And the results are... fine. It does not match Fable in real use."
Mollick's shader tests are not arbitrary. Creative demos — procedural shaders, Three.js scenes, interactive physics — are hard to fake: output either renders correctly or it doesn't. Mollick has used the same class of prompts across Fable 5, GPT-5.5, and now Fugu, making cross-model comparison unusually fair.
When he says Fugu "does not match Fable in real use," he is comparing against the same drowned-gothic-city / "make it better" workflow that Fable cleared in its first 72 hours. Benchmark tables don't capture that gap.
Other early reactions (June 22–23)
Tester
Observation
Ethan Mollick
30 min per shader test; results "fine" but below Fable; Harbor demo
Burned 100% of 5-hour quota in one prompt on a Three.js task; game "notably worse than GPT-5.5"; needed 7–8 Codex follow-ups to reach "almost playable"; fablepool.com/demo-fugu
Harbor scoring is subjective; dislikes Fugu's "overcardification" style (likely GPT-influenced UI patterns) vs GLM output
@wassieailouros
Local console run shows no reasoning trace during processing despite streaming enabled
Mollick's follow-up to a reply that Fugu is "a combination of LLMs":
"That would beat frontier LLMs, which it does not."
If multi-agent orchestration truly compounded frontier models, you'd expect super-linear quality. Early creative-coding tests suggest coordination overhead and latency eat the theoretical gain — at least on interactive visual tasks.
Benchmarks vs Harbor: the pattern
Dimension
Sakana's published benchmarks
Mollick / community testing
Task type
SWE-bench, LiveCodeBench, GPQA
Shaders, Three.js, interactive scenes
Latency
Not emphasized
30 min per shader test (Ultra-high)
Cost
Subscription framing
~$6 and full quota in 1 prompt (Steinberger)
Quality vs Fable
Claimed parity
Does not match in Mollick's words
vs GPT-5.5
Competitive on tables
Worse on Three.js (Steinberger); GPT-5.5 needed no follow-ups
This is the same benchmark vs real-use split we saw across the Fable 5 launch cycle: leaderboard numbers move markets; shader galleries move practitioners.
For teams blocked from Fable/Mythos by export controls, Fugu remains architecturally interesting — but June 23 testing suggests you should not assume benchmark parity transfers to creative coding or latency-sensitive work.
What Beta Users Built
Close to 500 early users put Fugu through real, demanding workflows during the beta. Three use cases stood out:
Code Review
"For code review, Fugu Ultra is significantly better than GPT-5.5. It gives comprehensive answers and finds the bugs others miss. Where other tools flag about three issues, Fugu surfaced more than twenty. It's become the model I run all my reviews through."
— Software Engineer
Long-Session Agent Products
"Raw output quality is on par with top frontier models, but Fugu showed unusually strong persona stability across long sessions, holding its identity where other models drift. For agent products, that may matter more than raw benchmark scores."
— Executive at Enterprise Platform Company
Security Assessment
"Given one scoped instruction, Fugu drove a full security assessment end-to-end — recon, XSS/SQLi checks, auth review, and a clean report with evidence and retest steps — staying inside scope and avoiding destructive actions."
— Cyber Security Engineer
The pattern across beta feedback is consistent: Fugu's value compounds on long, multi-step tasks. A single prompt doesn't reveal it. A 20-step research workflow does.
The Architecture Advantage
Traditional multi-agent systems require you to build the orchestration layer: pick models, define handoffs, write routing logic, handle failures. That complexity lives in your code.
Fugu internalizes it. The orchestration is trained, not hardcoded. This means:
No integration overhead — one API call, one endpoint
Dynamic routing — Fugu decides which specialist handles which subtask at runtime
Failure resilience — if an agent in the pool becomes unavailable, Fugu adapts
Automatic improvement — as better models enter the pool, performance improves without any change to your code
For developers, this is the equivalent of moving from managing your own servers to using a managed cloud service — except the managed layer is intelligence routing, not infrastructure routing.
Pricing and the Real Cost Math
Sakana Fugu has a subscription tier (around $20/month) for everyday use and a higher-tier plan for heavier workloads, plus pay-as-you-go for enterprise. Both Fugu and Fugu Ultra are on the same API — switching between them is a model parameter change.
That sounds reasonable on paper. The HN reaction on launch day was less charitable: "You pay $200/month to Anthropic, $200/month to OpenAI, $200/month to Cursor, $200/month to Google, and seeing that it didn't come to a nice round $1024/month, you pay $200/month to Sakana to coordinate it all."
The joke lands because it sounds like stacking yet another subscription. But the framing is wrong — and understanding why matters.
Fugu replaces your direct API subscriptions, it doesn't add to them. You pay Sakana one bill; Sakana pays Anthropic, OpenAI, and Google. The underlying API costs are absorbed into the subscription. You're not paying $200 to Sakana on top of paying $200 to each model provider — you're replacing those provider relationships with one managed layer.
Whether that's a good deal depends on a number factor.
The Token Fanout Problem
Multi-agent orchestration has a cost that's easy to miss in a flat subscription framing: every request fans out to multiple models.
When Fugu Ultra handles a complex task, it doesn't call one model. It typically:
Runs the orchestrator model to plan the approach (tokens consumed)
Fans out subtasks to 3–5 specialist models in parallel (3–5× tokens consumed)
Synthesizes outputs in a final consolidation pass (more tokens)
A single Fugu Ultra request can consume 4–6× the tokens of a direct single-model call for the same task. Sakana bundles all of this into the subscription pricing — but it's exactly why usage limits on cheaper tiers hit faster than you'd expect. Early users reported the $20 tier running out in under 5 hours of active use; direct Opus API access at comparable quality costs less per equivalent task.
The case for Fugu isn't cheaper tokens. It's cheaper results — the orchestrated output often requires fewer follow-up prompts, fewer iteration cycles, and fewer debugging rounds. That's a harder value to put in a table, which is why the sticker price comparison always looks unfavorable on first read.
The Margin Problem Every Aggregator Has
There's a structural economics problem Sakana shares with any model aggregator worth understanding.
When Anthropic charges $20/month for Claude Pro, their inference margin is roughly 70–80%. They make money on every token at scale. When Sakana charges for Fugu, they pay Anthropic, OpenAI, and Google full API rates — then add their own orchestration margin on top. You're paying the underlying model costs plus a layer.
This isn't a criticism of Sakana's model — it's just the reality of being an aggregator. The implication: Fugu's cost proposition only makes sense if the quality delta is real and happens on tasks you actually run. The beta feedback suggests it is, but only on high-value, multi-step work (code review, research automation, security assessment). For simpler tasks, you're paying Fugu Ultra prices for work a smaller model handles fine.
As a few people on HN noted, the math on individual usage can look similar to running near-free DeepSeek V4 on OpenRouter — which gets you good-enough quality at 1/10th the cost if your workload isn't demanding depth. Token prices are racing toward zero on the commodity end of the market. Fugu's bet is that deep orchestration quality doesn't commoditize at the same rate as raw tokens.
Who Should Actually Use This
Honest breakdown, use-case by use-case:
Scenario
Verdict
Individual dev, occasional prompting
Skip — OpenRouter or direct API is cheaper and more transparent
Worth evaluating — multi-vendor resilience and zero integration overhead have real value
Enterprise blocked from Fable/Mythos by export controls
Evaluate carefully — sovereignty story is real; creative-coding parity is unproven
Daily multi-step research or security assessment
Yes — Sakana beta feedback and benchmarks align here more than on Harbor-style tests
Light chat, autocomplete, RAG retrieval
No — you're paying orchestration overhead for tasks that don't need it
Budget-constrained solo developer
No — OpenRouter Fusion or a direct Opus/DeepSeek setup will cover most needs at a fraction of the cost
Latency-sensitive interactive work
No — 30-minute shader tests are disqualifying for most dev workflows
The $20 tier is an honest entry point to test whether Fugu's quality is real on your workloads before committing to a higher tier. The 5-hour-ish usage limit is tight — Steinberger exhausted his entire quota on one Three.js prompt. Run your own Harbor-equivalent test (shader, interactive scene, or multi-step agent task) before trusting benchmark tables.
Alternatives Worth Knowing
If Fugu doesn't fit after real-world testing, the multi-model orchestration space is getting crowded fast:
Direct Fable 5 / Opus 4.8 — if you have access, Mollick's tests suggest Fable still wins on creative coding. See when Fable 5 may return if you're blocked.
GPT-5.5 — Steinberger's Three.js test needed zero follow-ups vs Fugu's 7–8 Codex rounds
OpenRouter Fusion — calls N models, synthesizes with a final LLM. Open, cheap, transparent. Less intelligent routing than Fugu's trained orchestrator, but the gap is closing.
Databricks Omnigent — similar meta-harness architecture, targeting enterprise data workflows.
Roll your own — with OpenRouter plus a small orchestration harness, you can replicate much of what Fugu does if you have the engineering time. Sakana published two ICLR 2026 papers on how they built the routing model; the research is public.
What Comes Next
Sakana has flagged their roadmap priorities:
Expanding the agent pool — including open-weight models and Sakana's own upcoming models
Stronger long-running coordination — deeper support for multi-day agentic tasks
User control — more granular configuration of how Fugu orchestrates on your behalf
The architecture compounds naturally: every new capable model that enters the open ecosystem potentially enters Fugu's pool. Unlike a monolithic model that requires an expensive retraining cycle to improve, Fugu improves incrementally as the broader ecosystem does.
The Bigger Picture
The AI industry in 2026 has a geopolitical problem. Frontier capability is increasingly concentrated in a handful of US-based providers subject to export controls, regulatory changes, and policy shifts that can happen faster than engineering teams can adapt.
Sakana Fugu is the first production system explicitly designed around this constraint. It doesn't try to out-scale the frontier labs. It learns to coordinate them — and route around them when access disappears.
Whether that's enough to hold its position as Fable 5 evolves remains to be seen — and June 23 real-world testing suggests the gap on creative coding may be wider than benchmark slides imply. The architecture is still sound in theory: collective intelligence is more resilient than any single model. Whether Fugu Ultra delivers that collective advantage at acceptable latency and cost is now an open question practitioners are answering in public — starting with Mollick's Harbor gallery and Steinberger's fablepool demos.
Practical takeaway: treat Sakana's Fable-parity claims as a hypothesis. Run your own shader, agent, or research workflow before switching. Benchmarks rank models; Harbor benches reveal whether you'd actually ship with them.
Updated June 23, 2026 with Ethan Mollick's Harbor bench testing and community reactions. Benchmark scores reflect Sakana's June 22 release; real-world results may differ — verify on your workloads.