GeneBench-Pro: OpenAI''s Research-Level Benchmark for Computational Biology Judgment
OpenAI introduced GeneBench-Pro June 30, 2026 — 129 synthetic computational biology problems testing research taste, messy data QC, and iterative analysis. GPT-5.6 Sol scores 28.7% (31.5% Pro); human experts need 20–40 hours per task. Full breakdown with architecture diagrams, domain atlas, and grading design.
Scientific data rarely arrive with instructions. A computational biologist must decide whether a signal is biology or batch noise, whether the cohort supports the estimand, and when to abandon a first analysis plan. Recalling facts and running a canned pipeline are not the same skill.
On June 30, 2026, OpenAI introduced GeneBench-Pro — a research-level benchmark built to measure that harder layer: judgment-heavy analysis in computational biology. Greg Brockman amplified it July 1: problems that would take a human expert 20–40 hours each, with GPT-5.6 Sol as the current frontier result.
This post breaks down what GeneBench-Pro tests, how problems are built, where models fail, and why the scores matter for GPT-5.6 availability hype.
Update — July 11, 2026: OpenAI's $50K Bio Bounty stress-tests biosafety safeguards on GPT-5.6 the same week capability benchmarks rise — capability and red-team moving together.
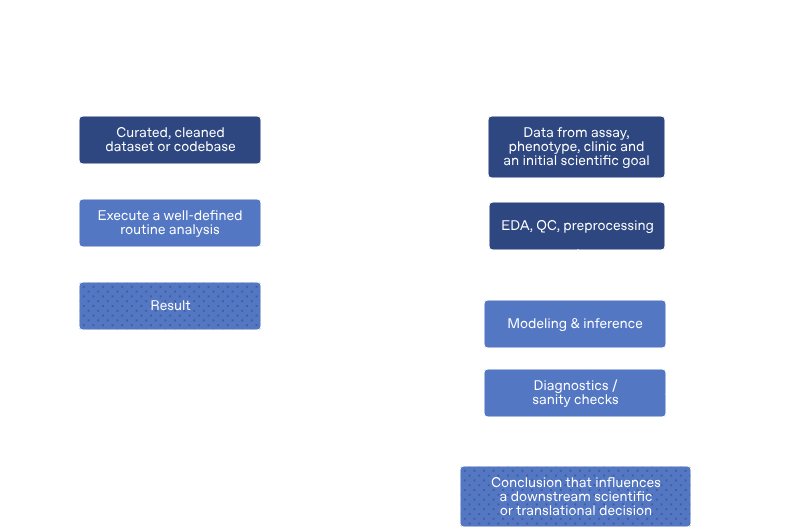
Most existing biology benchmarks stop early in the scientific workflow:
Typical benchmark scope
Real end-to-end analysis
Curated, cleaned dataset
Raw assay + phenotype + clinical context
Execute well-defined routine
EDA, QC, preprocessing — outliers? batch effects?
Result
Modeling + diagnostics + refinement loop
Conclusion that drives translational or clinical decision
OpenAI's diagram captures the gap explicitly:
GeneBench-Pro sits on the right column. Agents get messy realistic data, brief experimental context, and a target estimand tied to a downstream decision. Passing requires exploring data, picking an analysis path, iterating when diagnostics fail, and returning a numerically gradable answer.
OpenAI defines "research taste" as the chain of judgment calls: which questions the data can support, how early QC should change the model, when to revise the plan.
129 Problems Across Computational Biology
GeneBench-Pro spans genomics, quantitative biology, and translational medicine — expanding the earlier GeneBench line referenced in GPT-5.6 preview benchmarks.
Domain atlas (n=129):
Domain
n
Sub-domains (examples)
Population genetics
21
Admixture & aDNA, history & genealogies, selection & mutation
Example problem types on the case-studies page include CRISPR target validation, linked genetic locus mapping, carrier screening, parent-specific ancestry, and structural-variant-guided tumor therapy benefit–risk decisions — each with a concrete JSON answer contract and reasoning field.
Why Synthetic Data — Not Messy Historical Cohorts
Long-horizon biology benchmarks often fail in two opposite ways:
Too ambiguous — multiple defensible analysis paths; scores reflect benchmark author quirks, not model quality
Too insensitive — fundamental analysis errors still numerically pass
GeneBench-Pro's fix: simulate every dataset from a known structural causal model (SCM).
That enables:
Tuned complexity per problem
Acceptance bands so reasonable subjective choices still pass
Ablation proof that plausible wrong analyses fail
Trace audits for information leakage and shortcut paths
Deterministic grading against ground truth — no rubric verbosity games
External review:82 of 129 problems went to graduate students, postdocs, industry scientists, and professors — assessed for realism, identifiability, and appropriate estimators.
"The problems I reviewed would have been challenging for a graduate student to complete without iterated feedback from an experienced supervisor… they were not simply applying some off-the-shelf method to clean and well curated data."
— Alexander Strudwick Young, Assistant Professor in Human Genetics, UCLA
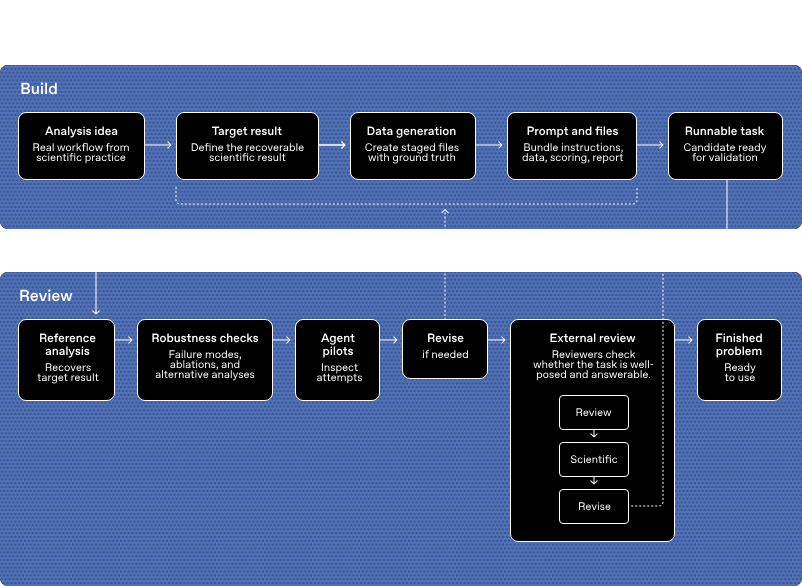
Construction and Validation Workflow
Each problem follows a build → review pipeline:
Build phase
Analysis idea — real workflow from scientific practice
Target result — recoverable scientific ground truth defined upfront
Data generation — staged files with embedded truth
Graders check numerical correctness and expect quality of analytical reasoning in the reasoning field — shortcuts are explicitly discouraged in prompts ("These data came from a real experiment… do not attempt to take any shortcuts.").
Results — GPT-5.6 Sol Leads, Room to Grow
Model / setting
GeneBench-Pro pass rate
GPT-5.6 Sol (highest reasoning)
28.7%
GPT-5.6 Sol + Pro mode
31.5%
GPT-5.6 Sol (lowest reasoning)
Single digits
GPT-5 (when GeneBench work began)
Below 5%
GPT-5.2 (high reasoning comparison)
~5× fewer solves than GPT-5.6 Sol at high reasoning, using more tokens
Scaling test-time compute: At lowest reasoning, GPT-5.6 Sol barely registers; at highest, it solves nearly six times as many questions as GPT-5.2 while using about two-thirds the tokens.
Open vs closed gap: The performance gap between GPT-5.6 / GPT-5.5 and leading open weights like GLM 5.2 is larger than coding benchmarks would predict — open models look more coding-specialized than strong at this kind of quantitative scientific judgment under uncertainty.
Bias concern addressed: OpenAI used frontier GPT models to evaluate problems during development and worried about pro-GPT bias. Competitor models at best matched contemporaneous GPT releases and often fell short.
Economics: Reviewers estimate 20–40 hours per problem. At $200/hr, human labor is thousands of dollars per task vs several dollars inference per agent run — partial automation at current ~30% pass rates could still move industrial genomics workflows if reliability improves on subsets.
OpenAI notes the benchmark may saturate by end of 2026 at current improvement pace — a bold claim that will invite scrutiny as Artificial Analysis runs the 50-question independent subset.
Where Models Fail — The Inferential Loop
Expert reviewers and failure traces cluster on predictable gaps:
Failure mode
Example
Data QC blindness
Ancestry swaps, C>T bias in ancient DNA, batch artifacts — agents "aren't cautious enough" (Lex Flagel, Gencove)
Wrong tool, right vibe
Conventional Cox when marginal structural models needed for treatment-confounder feedback
Partial progress
Observations without integrating into revised plan — novice pattern vs expert reframing
Solver contract sensitivity
Prompt wording changes which analyses appear permissible (Cyrillus Tan, NYGC)
Pharmacogenomic time-to-event example: GPT-5.5 fit a counting-process Cox with time-varying treatment but missed treatment-confounder feedback. GPT-5.6 Sol used a new-user marginal structural Cox model — excluded prevalent users, stabilized IP weights, 90-day efficacy lag — the causally appropriate path.
Models make partial progress on hard problems but struggle to close the inferential loop — mirror of expert vs novice cognition.
GeneBench-Pro vs LifeSciBench
Both landed in the same June 2026 research burst; they test different layers:
Sequencing is cheap; interpretation is the bottleneck. Biobanks link molecular, phenotypic, and EHR data at scale — but target prioritization still leans on human genetic evidence and teams of analysts.
If agents reliably automate even a fraction of GeneBench-Pro-class workflows:
Faster hypothesis triage and target follow-up
Shorter loop between data generation and go/no-go decisions
More reproducible exploratory analysis — if solver contracts stabilize
OpenAI's framing: future benchmarks must test abstraction-level scientific judgment, not book knowledge or routine .fit() pipelines — the same direction as TabFM-style zero-shot ML for structured data, but for causal genomics under mess.