LongCat-2.0: Meituan's 1.6T MoE Open Model Trained on AI ASIC Superpods
LongCat-2.0: 1.6T MoE, 48B active, 1M context, Terminal-Bench 70.8. Trained on 50K+ AI ASICs over 35T tokens. Claude Code, OpenClaw, Hermes — full guide.
Update — July 5, 2026: Meituan released LongCat-2.0's model weights and inference code to everyone, fully MIT licensed with no restrictions. The Hugging Face repo (meituan-longcat/LongCat-2.0) now ships real safetensors — BF16/F32 plus an FP8 variant and community quantizations — and the GPU/NPU deployment paths referenced at launch (SGLang PR, SGLang-FluentLLM for NPU) are live. The "weights coming soon" caveat below no longer applies — see How to access LongCat-2.0 today for the updated deployment steps.
June 30, 2026: Meituan open-sourced LongCat-2.0 — a 1.6 trillion-parameter MoE model with ~48B activated parameters per token, trained on 50,000+ AI ASIC accelerators over 35+ trillion tokens with no rollbacks or irrecoverable loss spikes. The same day X shipped hosted MCP servers and Fable 5 remained offline Day 18, another open-weight frontier coder entered the field.
This is not the LongCat Video Avatar talking-head model. LongCat-2.0 is Meituan's text/code/agent LLM — positioned for repository-level edits, automated task execution, and long-horizon agent workflows via Claude Code, OpenClaw, and Hermes.
Trained on 1M-context data (hundreds of billions of tokens)
Attention
LongCat Sparse Attention (LSA) — evolution of DeepSeek Sparse Attention
Training
50K+ AI ASIC superpods, 35T+ tokens, deterministic ops
Harnesses
Claude Code, OpenClaw, Hermes
Weights
Live since July 5, 2026 — Hugging Face, MIT licensed, no restrictions
Deployment
GPU (16x H20, SGLang) and NPU (SGLang-FluentLLM) — both documented
HN signal
43 points — community focused on ASIC training story and weight availability
Why LongCat-2.0 matters beyond the leaderboard
Three threads make this release bigger than another MoE drop:
1. Frontier training without Nvidia as the hero
Meituan states the full training run and large-scale deployment run on tens of thousands of AI ASIC superpods — not a mature Nvidia GPU stack. Community speculation on Hacker News points at Huawei Ascend 910C-class accelerators, though Meituan has not confirmed vendor publicly in the launch post.
The claim: 35+ trillion tokens pre-trained with no rollbacks or irrecoverable loss spikes — evidence that alternative hardware can sustain frontier-scale runs if you invest in deterministic operators, fault recovery, and memory-aware parallelism.
That is strategically significant while US export controls fragment access to Fable 5 and Nvidia-class compute remains concentrated.
2. Open weights in the Fable 5 vacuum
Day 18 of the Fable ban: international developers still need unrestricted frontier coders. Kimi K2.7-Code (June 12), GLM-5.2, and now LongCat-2.0 extend the open-weight ladder — each with different harness fit and hardware cost. As of July 5, LongCat-2.0's weights are no longer a promise: MIT-licensed safetensors are downloadable today, closing the one real gap (unavailable weights) that separated it from Kimi and GLM at launch.
3. Harness-native integration
LongCat-2.0 ships integrated with Claude Code, OpenClaw, and Hermes — not "API only, figure out agents yourself." Meituan measured Terminal-Bench 2.1 and SWE-bench Pro through Claude Code sandboxes, aligning with how explainx.ai readers actually evaluate models (Claude Code MCP guide, /mcp-servers).
Architecture — LSA, N-gram Embedding, and MoE at 1.6T
LongCat-2.0 builds on LongCat-Flash, pushing parameter efficiency and long-context speed.
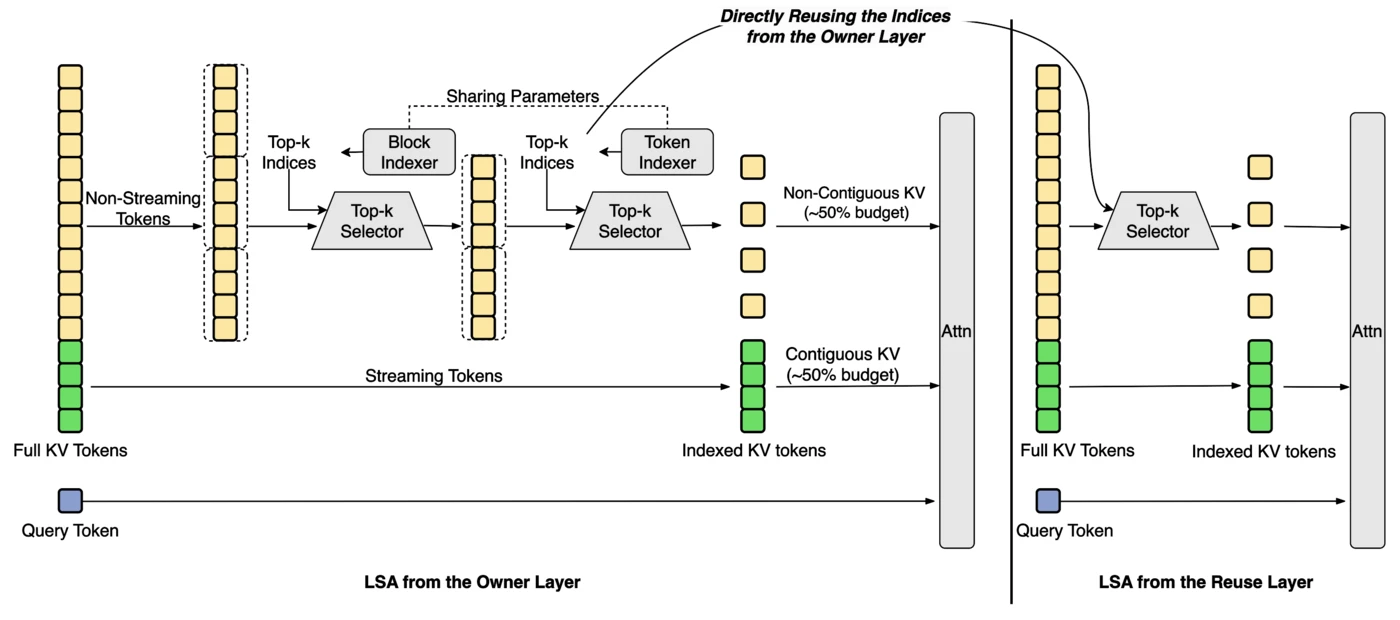
LongCat Sparse Attention (LSA)
Agent workloads drive long-input processing. DeepSeek Sparse Attention (DSA) uses fine-grained sparsity, but Meituan profiles the Lightning Indexer as a bottleneck (output discontinuity, quadratic scoring cost).
LSA adds three orthogonal indexer improvements:
Component
What it does
Streaming-aware Indexing (SI)
Reshapes token selection for coalesced HBM access — contiguous reads instead of fragmented scatter
Cross-Layer Indexing (CLI)
One indexing pass serves multiple consecutive layers at inference — saliency stable across adjacent layers
Hierarchical Indexing (HI)
Coarse-to-fine scoring — block-level recall, then fine token selection inside candidates
LSA extends to Multi-Token Prediction (MTP) for speculative decoding: draft and target models share indexing passes across MTP steps.
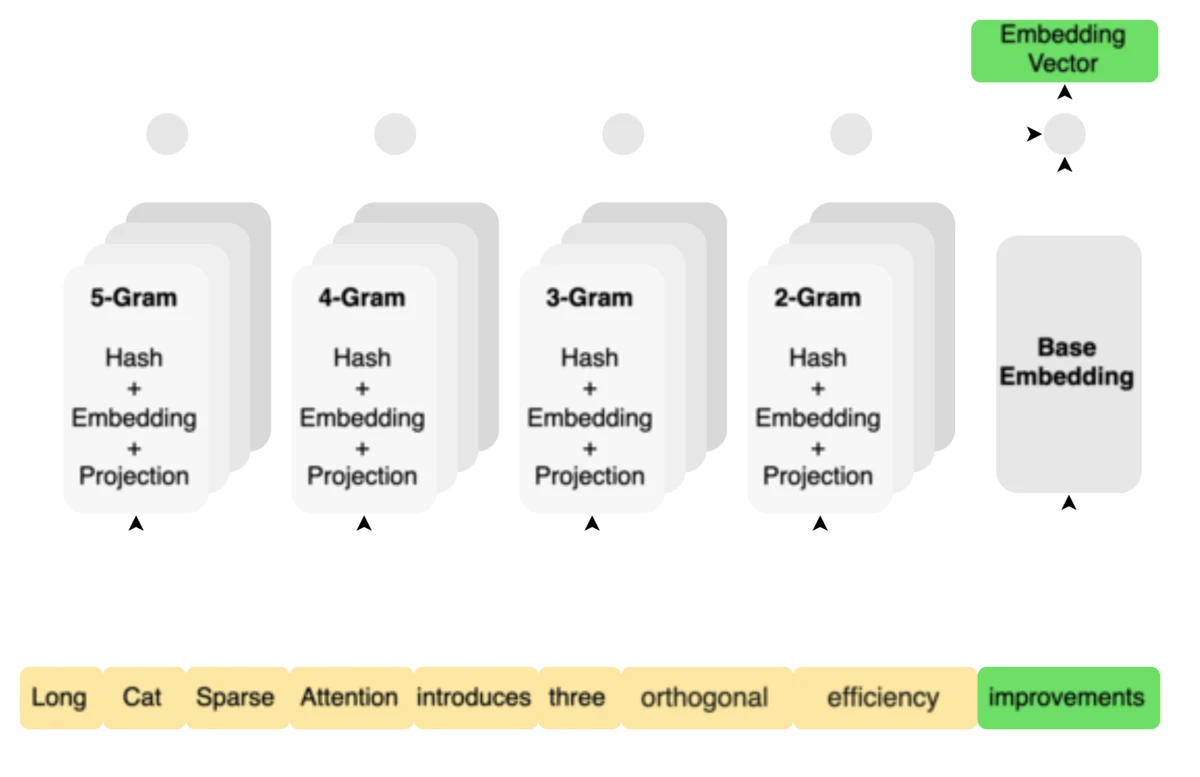
N-gram Embedding (135B parameters)
LongCat-2.0 adds 135B N-gram Embedding parameters (n-gram size 5) — expanding the embedding space ~100× via token combinations. Meituan's scaling logic:
MoE sparsity is already ~97% — adding 135B more experts yields negligible gain
N-gram Embedding at equivalent scale beats pure expert scaling
N-gram share kept under 10% of total budget — above 50% diminishing returns
Inference benefit: shifting params from experts to N-gram Embedding reduces large-batch decoding memory I/O.
Scale summary
Parameter
LongCat-2.0
Kimi K2.7-Code (comparison)
Total params
1.6T
1T
Active per token
~48B
32B
Context training
Up to 1M
256K
Attention
LSA (sparse)
MLA
Training infrastructure — 50K ASICs and deterministic ops
Meituan's infrastructure section is unusually detailed for a launch blog — worth reading in full on longcat.chat/blog/longcat-2.0.
Highlights:
50K+ AI ASICs for pretraining; 6D parallelism including EMBP for N-gram Embedding
Superpods — up to 48 machines each, all-to-all inside, RoCE between pods → ~30% pretraining throughput gain
Deterministic operators across Embedding, FA, LSA, MoE — reproducible production training
Muon optimizer at scale with symmetric matmul kernels
1M context via CP parallelism scaled to 512+, balanced batch partitioning
Fault recovery — automated link isolation and rejoin after stress tests; bit-flip detection on hot operators
HN takeaway: the software community around non-Nvidia ASICs is "still less developed" (Meituan's words) — they built custom stacks to compensate. If Ascend-class clusters can train 1.6T MoE cleanly, the compute diversification narrative accelerates.
Benchmarks — code, agents, and foundations
Scores from Meituan's table. * = external reported metrics; others in-house unified harness. "-" = not available.
SWE-bench series — Claude Code; 4c8g sandbox; temp 1.0, top_p 1.0; problematic tasks corrected
LongCat-2.0 edges Gemini 3.1 Pro on Terminal-Bench in this table and sits between GPT-5.5 and Opus 4.7 on SWE-bench Pro — but trails Opus 4.8 on all three code-agent columns where external numbers exist.
Honesty filter: these are mostly Meituan-measured except starred externals. Independent reproduction on DevThrottle and community harnesses typically lags open-weight launches by 1–2 weeks. Treat launch numbers as directional until third parties confirm.
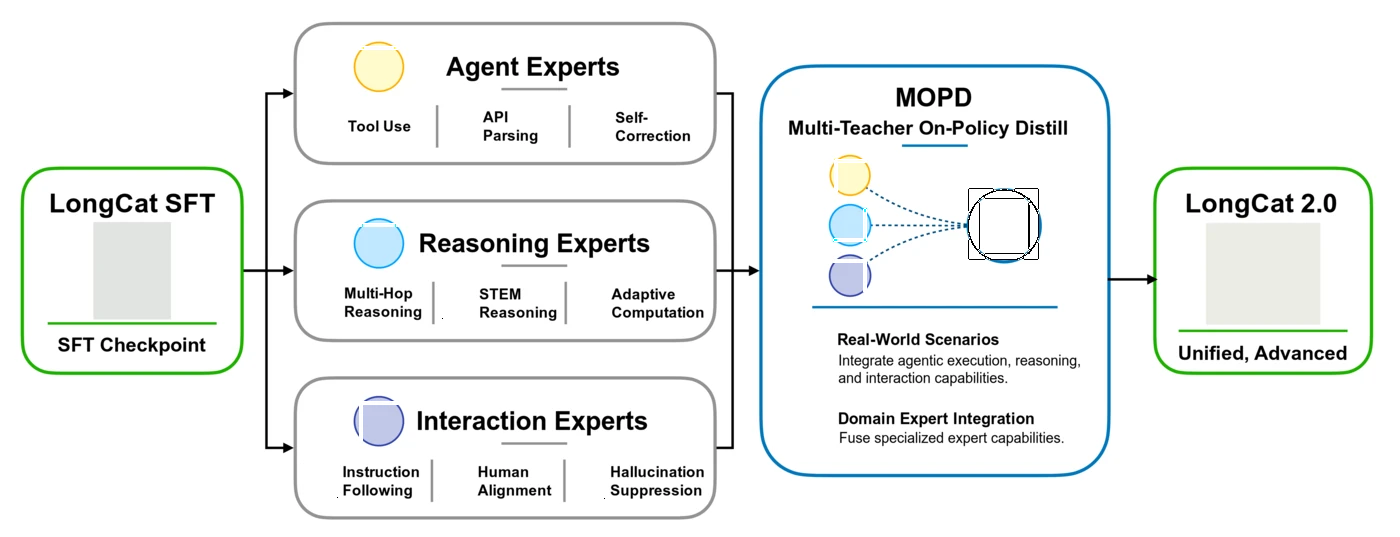
Post-training — Agent, Reasoning, and Interaction experts
LongCat-2.0 uses a MOPD multi-expert post-training architecture:
Fusion via MOPD combines agentic execution, reasoning depth, and alignment — the same "specialist merge" pattern other Chinese labs use when one base MoE serves multiple product surfaces.
Demos — what Meituan claims in production
The launch page includes scenario tabs: codebase migration (full plugin rewrite to new SDK), web app development, agentic research, data analysis, presentation generation, and creative writing.
The codebase migration demo is the developer hook: read full repo + migration docs, map architecture, rewrite plugin preserving behavior, compile clean on first build — the same long-horizon promise Kimi K2.7-Code markets.
How to access LongCat-2.0 today
Updated July 5, 2026 — weights and inference code are public:
Self-hosting reality check: the weights are real now, but the hardware bar hasn't moved. At 1.6T total parameters, even 2-bit quantization implies ~400GB+ of weight storage before KV cache — Meituan's own reference deployment is 2 nodes of 16x H20 GPUs. This is a datacenter model; llama.cpp support for LongCat's architecture is not yet confirmed, so plan on Transformers + vLLM/SGLang rather than consumer inference stacks.
Community reaction — Hacker News, June 30
The HN thread (~43 points, 3 hours after launch) split three ways:
1. ASIC training is the real story
"This is the real news story... frontier-scale training on alternative hardware platforms." — gardnr
Speculation: Huawei Ascend 910C clusters. If true, LongCat-2.0 is evidence of non-Nvidia frontier pretraining at 1.6T scale — geopolitically parallel to the Fable export-control fight.
2. Weights not yet downloadable (resolved July 5)
At launch, Hugging Face repo was live but weights pending, and GitHub links reportedly 404'd per early commenters. That gap closed on July 5, when Meituan pushed full safetensors, the MIT license file, and working inference-code links for both GPU and NPU.
3. Early quality probes mixed
One HN user tested a nuclear-reactor fuel question — LongCat gave a well-reasoned but incorrect answer (Pu-241 vs U-235); Qwen 3.7 Plus and Gemini Flash answered correctly. n=1 — not a verdict, but a reminder to eval on your domain before production routing.
4. Architecture lineage
Discussion of DeepSeek Sparse Attention lineage — Meituan extends DSA with LSA rather than shipping a pure finetune of DeepSeek V4-Pro, though architectural debt to DeepSeek's sparse-attention research is acknowledged in the community. The question resurfaced on X after the July 5 weight drop, with one reply pressing Meituan on how LongCat-2.0 differs from "DeepSeek V4 Pro, which LongCat 2 is clearly based on and built on" — Meituan has not published a direct rebuttal beyond the LSA architecture notes above.
Reaction after the July 5 weight release
The open-weight drop pulled in a second wave of commentary on X, distinct from the launch-day Hacker News thread:
Real production use, not just benchmarks. One developer reported running LongCat-2.0 as the "aggregate synthesizer" in a mixture-of-agents pipeline — a token-heavy role — and described the output quality on complex synthesis tasks as reading "like a book."
1M context lands as a genuinely new capability, not a spec-sheet number. With weights actually downloadable, the reaction to the 1M-token context window shifted from skepticism to visceral: several replies noted that an entire mid-size codebase now fits in a single prompt.
API access lags the open-weight release for international users. A US-based fan of the earlier LongCat-1.0 asked how to pay for API access from outside China; Meituan's official account confirmed international payment support is still "under active development," meaning self-hosting via Hugging Face is currently the more reliable path for developers outside Meituan's home market.
Community support moved to Discord. Meituan is now directing setup and deployment questions to its Discord server rather than GitHub issues alone.
LongCat-2.0 vs Kimi K2.7 vs GLM-5.2 — June 2026 open coder map
Practical guidance: all three (Kimi, GLM, LongCat) now have downloadable weights — the choice is hardware fit and license, not availability. LongCat is the largest and most compute-hungry of the three (16x H20 reference deployment); watch for independent SWE-bench reproduction before routing production traffic. Keep Opus 4.8 as closed baseline until Fable returns.
Pull the weights — confirmed live on Hugging Face under MIT since July 5; verify the FP8 or quantized variant matches your hardware before the full BF16 checkpoint
Reproduce Terminal-Bench / SWE-bench on your harness — Meituan used Claude Code sandboxes
Long-context tasks — 1M training claim needs validation on your repo-scale traces
Domain probes — STEM, legal, medical; HN's nuclear physics example shows reasoning gaps on niche factual chains
Cost — API pricing TBD at scale; self-host requires datacenter budget
Bottom line
LongCat-2.0 is Meituan's bid for open-weight frontier agents — larger than Kimi K2.7, trained on AI ASIC superpods at 1.6T / 48B active, with credible in-house coding benchmarks and Claude Code / OpenClaw / Hermes integration on day one.
The headline for infrastructure watchers: 35T tokens, zero irrecoverable spikes, 50K ASICs — frontier training is no longer exclusively an Nvidia story.
The headline for developers: weights are live and MIT licensed as of July 5, Opus 4.8 still leads on external SWE-bench numbers in Meituan's own table, and Fable 5 is still offline — LongCat joins the open ladder, not the closed frontier restore.
Run your eval when weights drop. The benchmark that matters is on your codebase.
LongCat-2.0 specs and benchmarks accurate as of June 30, 2026 per longcat.chat/blog/longcat-2.0; weight-release and licensing details updated July 6, 2026 following Meituan's July 5 open-source announcement. Verify current Hugging Face weight status, API pricing, and independent benchmark reproduction before production use.