
Claude Opus 4.7 is Anthropic’s new flagship in the Claude 4 line: positioned for the hardest reasoning and agentic coding workloads, with larger outputs than Sonnet 4.6 and a knowledge cutoff that tracks early 2026 on the public comparison grid.
This article summarizes Anthropic’s own models documentation (feature table, pricing, limits, rollout footnotes) and adds a benchmark comparison figure (Opus 4.7 vs Opus 4.6, GPT-5.4, Gemini 3.1 Pro, and Mythos Preview) so you can see where gains show up—especially agentic coding and vision reasoning.
Primary references
- Models overview — Claude Docs (structure and “choosing a model” guidance)
- Anthropic pricing (full token economics, caching, batch)
- In-product docs paths you may see in the console: What’s new in Claude Opus 4.7, Migration guide, Model cards
Why Anthropic says to start with Opus 4.7 for “the hard stuff”
Claude Docs frame the decision simply: if you are unsure, consider Opus 4.7 for the most complex tasks—it is described as the most capable generally available model, with a step-change improvement in agentic coding over Claude Opus 4.6.
All current Claude models in that overview support text + image in, text out, multilingual use, and vision, with access via Claude API, Amazon Bedrock, Google Vertex AI, and Microsoft Foundry.
Latest models at a glance (from Anthropic’s comparison table)
Figures below are as stated in Anthropic’s public “Latest models comparison”—always re-check Docs for API IDs, aliases, and third-party IDs, which can change with snapshots.
| Feature | Claude Opus 4.7 | Claude Sonnet 4.6 | Claude Haiku 4.5 |
|---|---|---|---|
| Positioning | Most capable GA model for complex reasoning & agentic coding | Best speed + intelligence balance | Fastest; near-frontier intelligence |
| Pricing (API) | $5 / input MTok · $25 / output MTok | $3 / input · $15 / output | $1 / input · $5 / output |
| Extended thinking | No | Yes | Yes |
| Adaptive thinking | Yes | Yes | No |
| Priority tier | Yes | Yes | Yes |
| Latency (relative) | Moderate | Fast | Fastest |
| Context window | 1M tokens | 1M tokens | 200k tokens |
| Max output (sync Messages API) | 128k tokens | 64k tokens | 64k tokens |
| Reliable knowledge cutoff | Jan 2026 | Aug 2025 | Feb 2025 |
| Training data cutoff | Jan 2026 | Jan 2026 | Jul 2025 |
Footnotes from the same page worth keeping in your runbook:
- Pricing — batch discounts, prompt caching, extended thinking surcharges, and vision fees live on the dedicated pricing doc.
- Cutoffs — “reliable knowledge cutoff” vs broader training data cutoff are defined in Anthropic’s Transparency Hub.
- AWS — Claude Opus 4.7 on Bedrock is called out as research preview in the comparison (availability may differ from API).
- Batches — on Message Batches API, Anthropic notes Opus 4.7, Opus 4.6, and Sonnet 4.6 can reach up to 300k output tokens with the
output-300k-2026-03-24beta header (per Docs).
Claude Mythos Preview (separate track)
Docs stress that Claude Mythos Preview is not bundled into the standard trio above: it is a research preview aimed at defensive cybersecurity workflows under Project Glasswing, invitation-only, with no self-serve sign-up. If you are evaluating red-team / vuln research capabilities, treat Mythos as a different product surface than everyday Opus 4.7 app development.
For more on how Anthropic has publicly framed Mythos and Glasswing on the security blog, see our earlier note: Claude Mythos Preview and cybersecurity.
Benchmark highlights: Opus 4.7 vs peers (including agentic coding)
Anthropic’s models marketing / evaluation collateral includes a wide benchmark grid comparing Opus 4.7 to Opus 4.6, GPT-5.4, Gemini 3.1 Pro, and Mythos Preview across agentic coding, terminal coding, reasoning, tool use, computer use, finance, security, vision, and multilingual tasks.
Below is the official-style comparison graphic (saved locally for fast loading). Mythos Preview appears as a research trajectory—not a drop-in substitute for GA Opus.
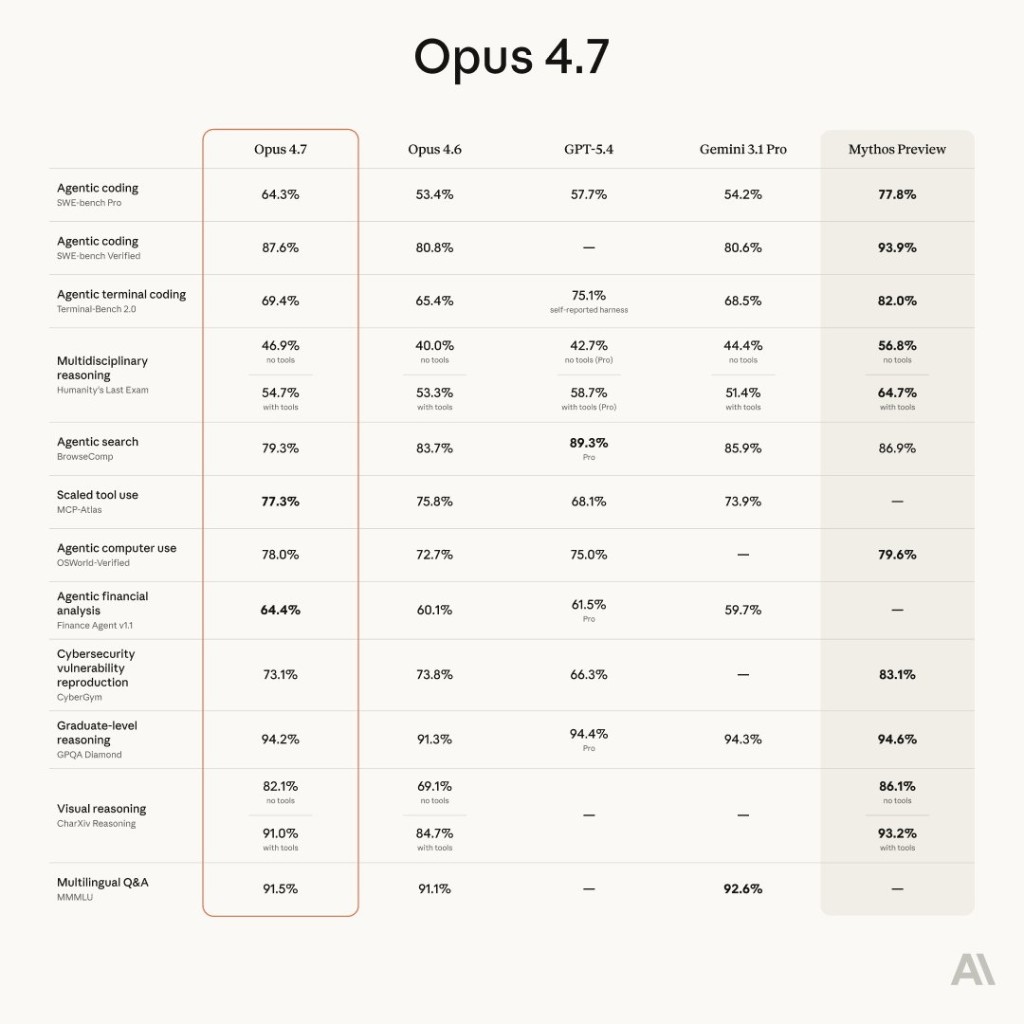
Same data as an accessible table
| Area | Benchmark | Opus 4.7 | Opus 4.6 | GPT-5.4 | Gemini 3.1 Pro | Mythos Preview |
|---|---|---|---|---|---|---|
| Agentic coding | SWE-bench Pro | 64.3% | 53.4% | 57.7% | 54.2% | 77.8% |
| Agentic coding | SWE-bench Verified | 87.6% | 80.8% | — | 80.6% | 93.9% |
| Agentic terminal coding | Terminal-Bench 2.0 | 69.4% | 65.4% | 75.1% | 68.5% | 82.0% |
| Multidisciplinary reasoning | Humanity’s Last Exam (no tools) | 46.9% | 40.0% | 42.7% | 44.4% | 56.8% |
| Multidisciplinary reasoning | Humanity’s Last Exam (with tools) | 54.7% | 53.3% | 58.7% | 51.4% | 64.7% |
| Agentic search | BrowseComp | 79.3% | 83.7% | 89.3% | 85.9% | 86.9% |
| Scaled tool use | MCP-Atlas | 77.3% | 75.8% | 68.1% | 73.9% | — |
| Agentic computer use | OSWorld-Verified | 78.0% | 72.7% | 75.0% | — | 79.6% |
| Agentic financial analysis | Finance Agent v1.1 | 64.4% | 60.1% | 61.5% | 59.7% | — |
| Cybersecurity | CyberGym (vuln reproduction) | 73.1% | 73.8% | 66.3% | — | 83.1% |
| Graduate-level reasoning | GPQA Diamond | 94.2% | 91.3% | 94.4% | 94.3% | 94.6% |
| Visual reasoning | CharXiv Reasoning (no tools) | 82.1% | 69.1% | — | — | 86.1% |
| Visual reasoning | CharXiv Reasoning (with tools) | 91.0% | 84.7% | — | — | 93.2% |
| Multilingual Q&A | MMMLU | 91.5% | 91.1% | — | 92.6% | — |
*Percentages are as printed on Anthropic’s benchmark figure; leaderboard definitions, prompts, and tool policies can move scores over time—treat this as a snapshot, not a substitute for your eval harness.
Reading the table pragmatically
- Agentic coding (SWE-bench Pro / Verified) is where Opus 4.7 shows a large jump vs 4.6 in this grid.
- Terminal-Bench still shows GPT-5.4 ahead in this particular column—use both IDE and terminal tasks when you regression-test.
- Tools materially move HLE and CharXiv scores—if your product gives the model browsers, IDEs, or MCP, mirror that in evals.
- Mythos Preview leads several security / exploit-adjacent rows here but is not a general GA replacement for Opus.
Migrating from Opus 4.6 (or older)
Anthropic explicitly recommends migrating to Opus 4.7 if you are on Opus 4.6 or older, to pick up intelligence and agentic coding gains. Follow their Migrating to Claude Opus 4.7 doc for request shape, snapshot IDs, and fallback strategy.
If you are building agents and skills, not just chat
Stronger agentic coding models change the ROI of structured playbooks:
- What are agent skills? —
SKILL.md, progressive disclosure, MCP - Skills registry — installable community skills ranked by adoption
- MCP servers directory — tool surfaces models can call reliably
Opus 4.7 doesn't remove the need for clear tools, tests, and human review—it raises the ceiling on how much end-to-end work a single agent session can complete when those guardrails exist.
Update — July 14, 2026: Anthropic maps Claude's expressed values — Opus 4.7 leans caution (+0.24σ) and depth (+0.23σ), matching user reports of more pushback and candid critique vs Sonnet 4.6.
Related Posts
- Anthropic Files Confidential S-1 with SEC: AI Safety Leader Eyes IPO
- The Agentic Era: How AI Agents Will Transform Everything (2026-2030)
- Anthropic Claude Managed Agents: Dreaming and Multiagent Orchestration
- What are agent skills? Complete guide
Bottom line
Claude Opus 4.7 is Anthropic’s new default “go big” recommendation for hard reasoning and agentic coding, with 128k-class outputs, 1M context, and early-2026 knowledge on the public card—priced at a premium vs Sonnet and Haiku. The benchmark figure underscores coding and vision as headline movers, while Mythos Preview remains a separate, invitation-only security track.
For live API strings, Bedrock / Vertex IDs, and deprecations, always treat Claude Docs — Models as source of truth.
This article is an independent summary for developers on explainx.ai and is not sponsored by Anthropic. Numbers and feature flags are transcribed from Anthropic’s public documentation and benchmark collateral as of the article date; verify before production rollouts.